
Apache Iceberg optimization: Solving the small files problem in Amazon EMR
AWS Big Data
OCTOBER 3, 2023
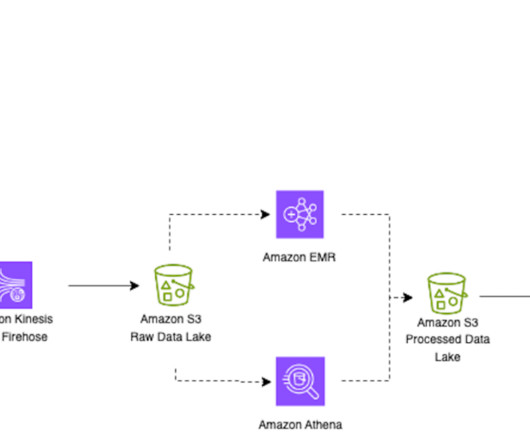
For our testing, we generated about 58,176 small objects with total size of 2 GB. For running the Amazon EMR tests, we used Amazon EMR version emr-6.11.0 Check the snapshot table to see that a new snapshot is created for the table with the operation replace. with Spark 3.3.2, and JupyterEnterpriseGateway 2.6.0.




















Let's personalize your content