

Automate discovery of data relationships using ML and Amazon Neptune graph technology
AWS Big Data
APRIL 19, 2023
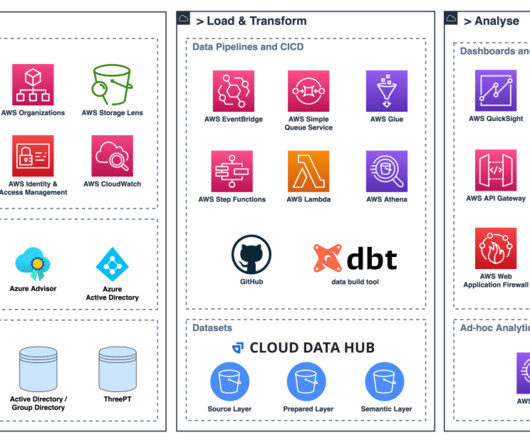
Independent data products often only have value if you can connect them, join them, and correlate them to create a higher order data product that creates additional insights. A modern data architecture is critical in order to become a data-driven organization.





















Let's personalize your content