
Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
AWS Big Data
NOVEMBER 9, 2023
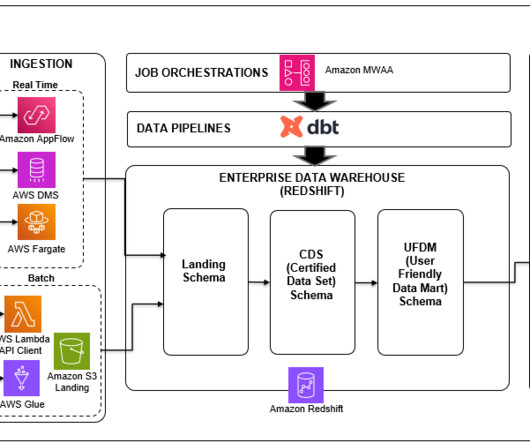
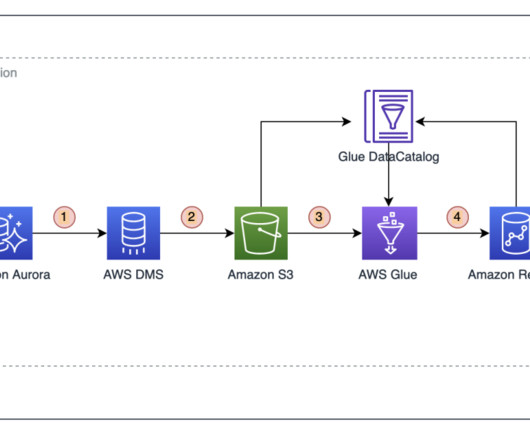
It does this by helping teams handle the T in ETL (extract, transform, and load) processes. It allows users to write data transformation code, run it, and test the output, all within the framework it provides. As part of their cloud modernization initiative, they sought to migrate and modernize their legacy data platform.



















Let's personalize your content