

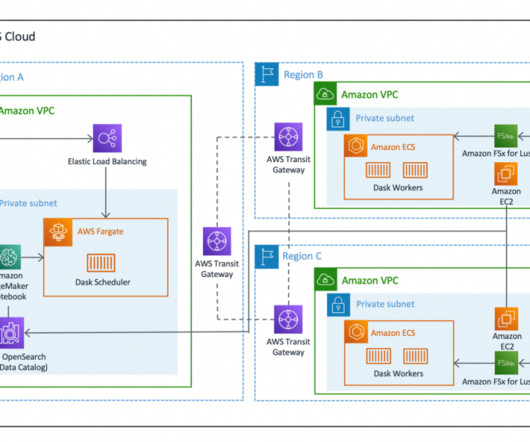
Build efficient, cross-Regional, I/O-intensive workloads with Dask on AWS
AWS Big Data
MAY 4, 2023
Unnecessary data transfer on the petabyte scale is costly, slow, and consumes energy. A key feature of Lustre is that only the file system’s metadata is synced. Worker clusters scale based on CPU usage, provision additional workers in extended periods of demand, and scale down as resources become idle.










Let's personalize your content