

Apache Ozone Powers Data Science in CDP Private Cloud
Cloudera
AUGUST 26, 2021
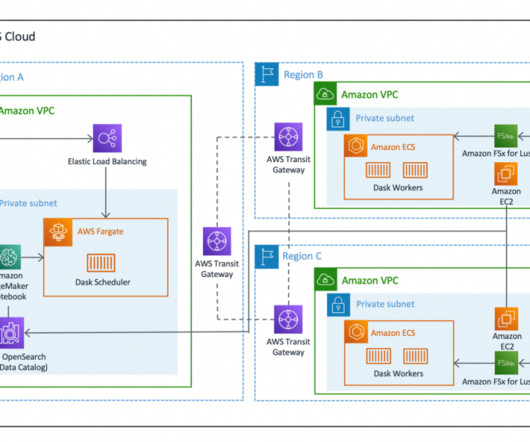
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. awsAccessKey=s3-spark-user/HOST@REALM.COM. Ozone Namespace Overview.



























Let's personalize your content