
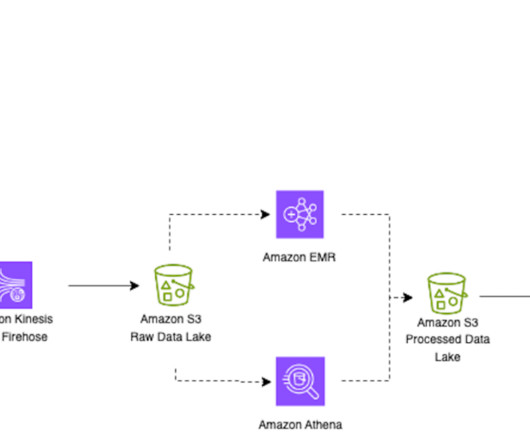
Apache Iceberg optimization: Solving the small files problem in Amazon EMR
AWS Big Data
OCTOBER 3, 2023
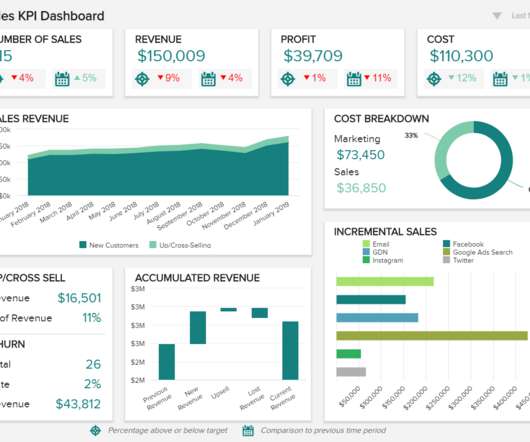
Compaction is the process of combining these small data and metadata files to improve performance and reduce cost. Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. with Spark 3.3.2,



























Let's personalize your content