
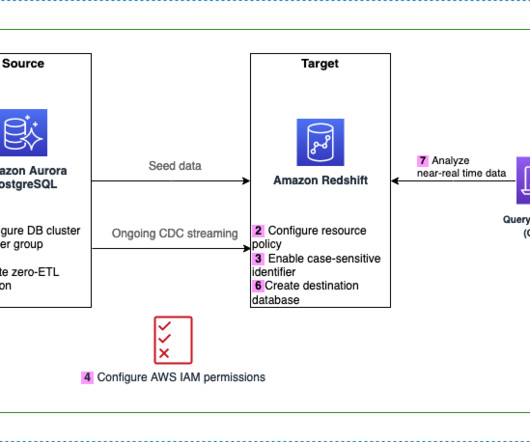
Achieve near real time operational analytics using Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift
AWS Big Data
APRIL 10, 2024
When data is used to improve customer experiences and drive innovation, it can lead to business growth,” – Swami Sivasubramanian , VP of Database, Analytics, and Machine Learning at AWS in With a zero-ETL approach, AWS is helping builders realize near-real-time analytics.























Let's personalize your content