

Use Apache Iceberg in your data lake with Amazon S3, AWS Glue, and Snowflake
AWS Big Data
APRIL 3, 2024
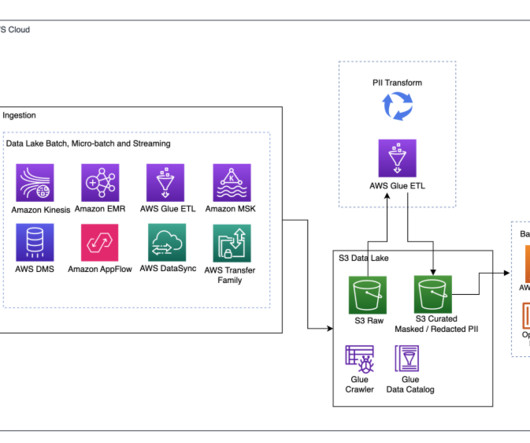
They understand that a one-size-fits-all approach no longer works, and recognize the value in adopting scalable, flexible tools and open data formats to support interoperability in a modern data architecture to accelerate the delivery of new solutions.
















Let's personalize your content