
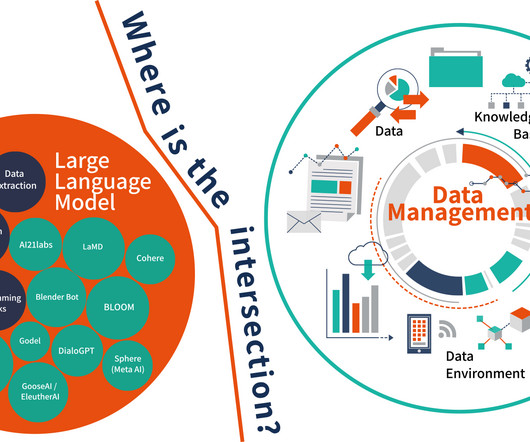
Large Language Models and Data Management
Ontotext
JULY 24, 2023
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and data management. But there are also a host of other issues (and cautions) to take into consideration. Another concern relates to the definition of ‘data constraints.’













Let's personalize your content