
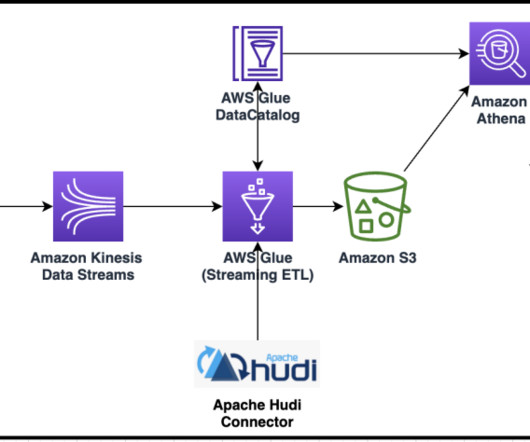
Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight
AWS Big Data
AUGUST 3, 2023
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates data integration workloads in AWS.














Let's personalize your content