

Load data incrementally from transactional data lakes to data warehouses
AWS Big Data
OCTOBER 19, 2023
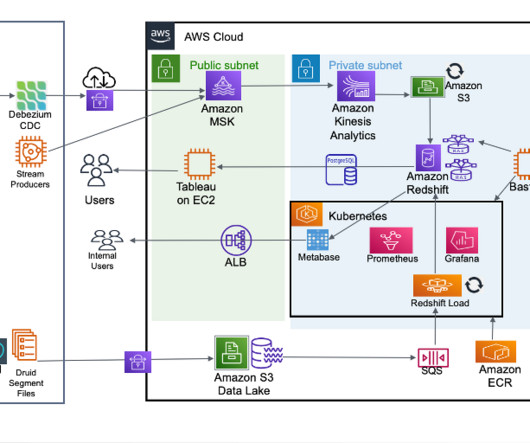
Data lakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure.

















Let's personalize your content