
From Data Silos to Data Fabric with Knowledge Graphs
Ontotext
SEPTEMBER 15, 2020
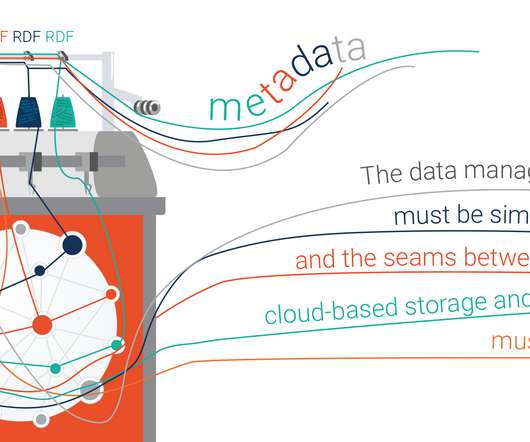
The Data Fabric paradigm combines design principles and methodologies for building efficient, flexible and reliable data management ecosystems. Knowledge Graphs are the Warp and Weft of a Data Fabric. To implement any Data Fabric approach, it is essential to be able to understand the context of data.













Let's personalize your content