
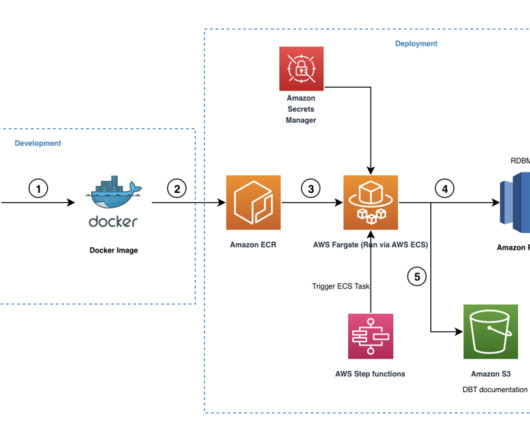
Implement data warehousing solution using dbt on Amazon Redshift
AWS Big Data
NOVEMBER 17, 2023
For more information, refer SQL models. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. Tests – These are assertions you make about your models and other resources in your dbt project (such as sources, seeds, and snapshots). For more information, refer to Redshift set up.
































Let's personalize your content