
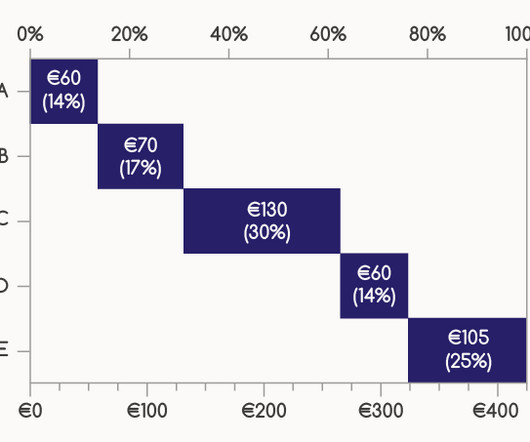
Chart Snapshot: Progressive Bar Charts
The Data Visualisation Catalogue
MARCH 1, 2024
Progressive Bar Charts sometimes include an additional bar representing the total of all individual segments, providing viewers with a clear reference point for the overall value.









































Let's personalize your content