

Build and manage your modern data stack using dbt and AWS Glue through dbt-glue, the new “trusted” dbt adapter
AWS Big Data
NOVEMBER 29, 2023
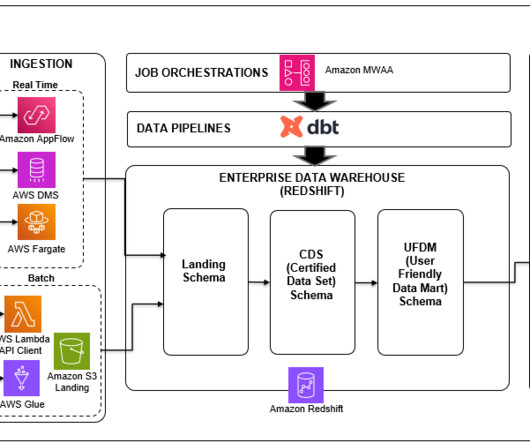
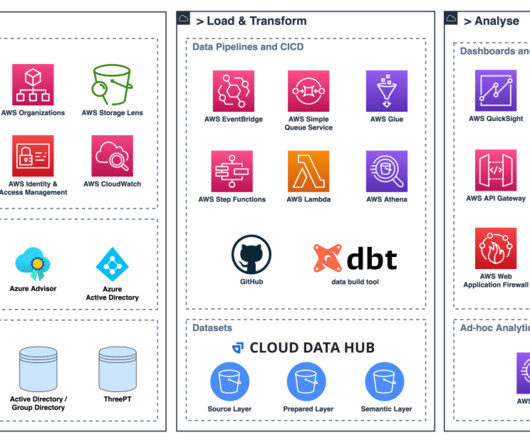
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by data warehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.





















Let's personalize your content