

Reference guide to build inventory management and forecasting solutions on AWS
AWS Big Data
APRIL 11, 2023
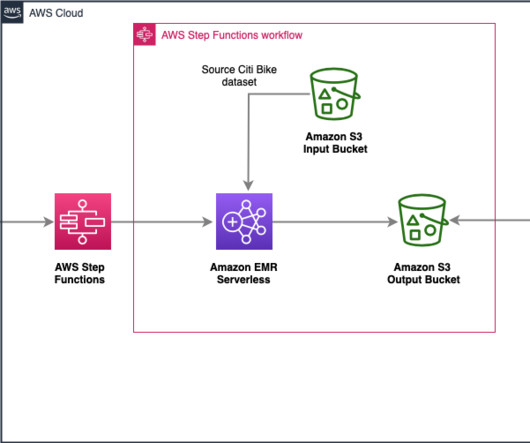
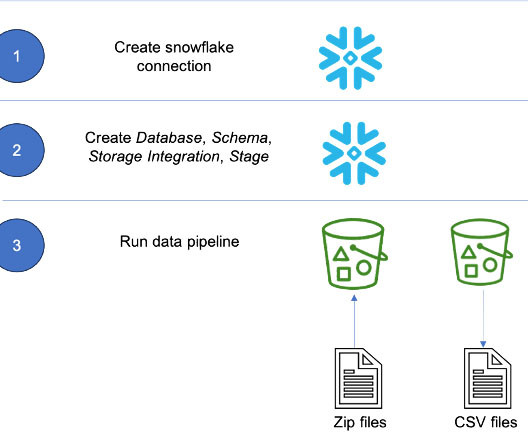
Accurately predicting demand for products allows businesses to optimize inventory levels, minimize stockouts, and reduce holding costs. Solution overview In today’s highly competitive business landscape, it’s essential for retailers to optimize their inventory management processes to maximize profitability and improve customer satisfaction.











Let's personalize your content