
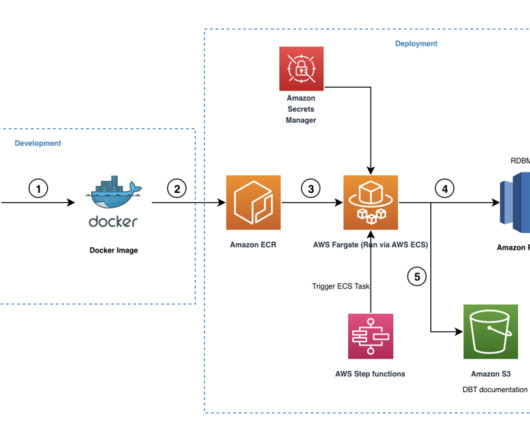
Implement data warehousing solution using dbt on Amazon Redshift
AWS Big Data
NOVEMBER 17, 2023
Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your data warehouse using the dbt seed command. An Amazon Simple Storage (Amazon S3) bucket to host documentation files.
























Let's personalize your content