
Build a decentralized semantic search engine on heterogeneous data stores using autonomous agents
AWS Big Data
MAY 28, 2024
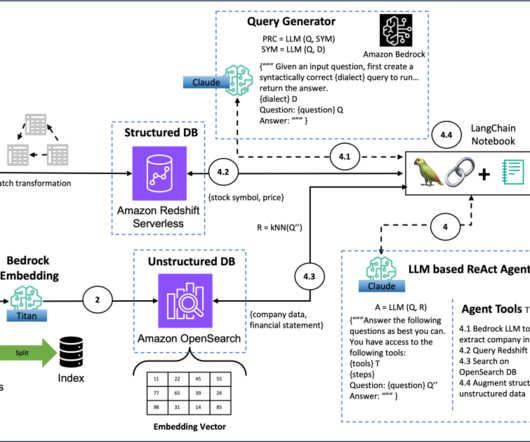
Large language models (LLMs) such as Anthropic Claude and Amazon Titan have the potential to drive automation across various business processes by processing both structured and unstructured data. This would allow analysts to process the documents to develop investment recommendations faster and more efficiently.




















Let's personalize your content