


Break data silos and stream your CDC data with Amazon Redshift streaming and Amazon MSK
AWS Big Data
DECEMBER 13, 2023
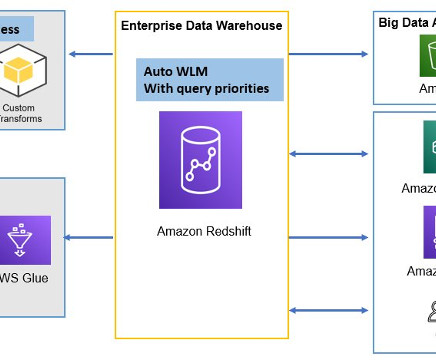
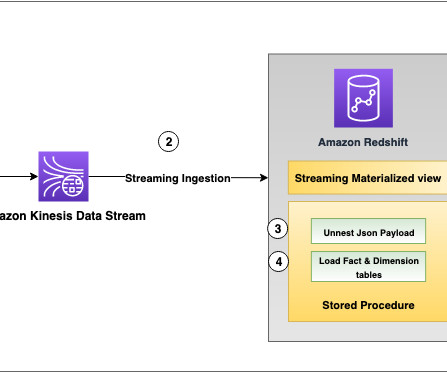
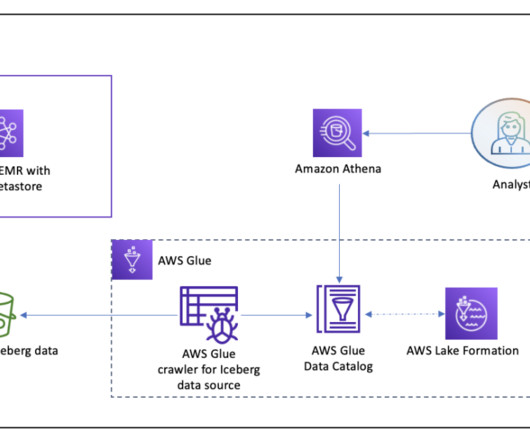
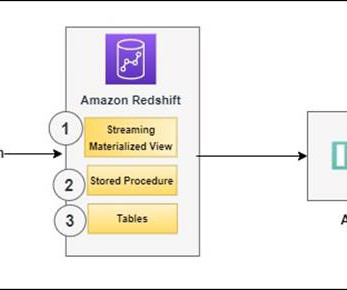
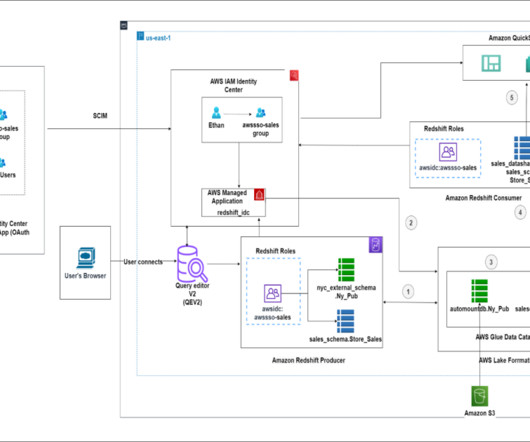
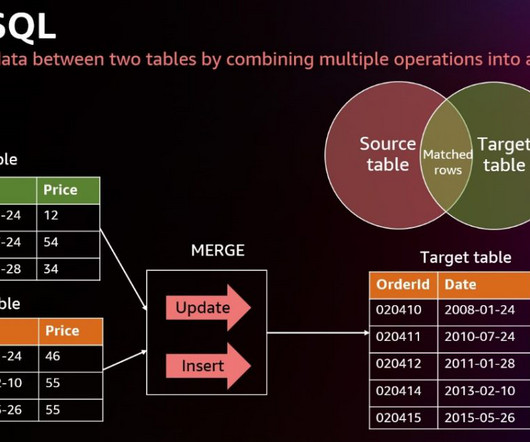
Data loses value over time. Traditionally, customers used batch-based approaches for data movement from operational systems to analytical systems. A batch-based approach can introduce latency in data movement and reduce the value of data for analytics. You can create materialized views using SQL statements.





































Let's personalize your content