
Amazon OpenSearch Service Under the Hood : OpenSearch Optimized Instances(OR1)
AWS Big Data
APRIL 17, 2024
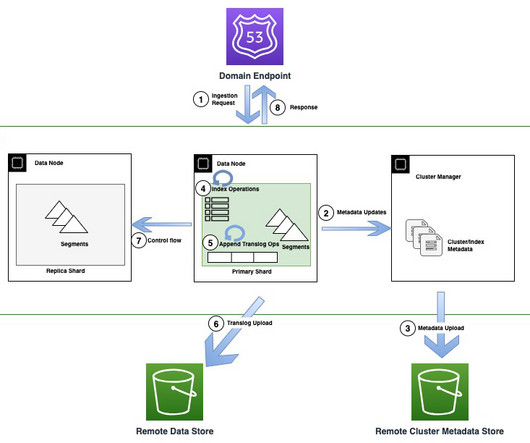
The following diagram illustrates an indexing flow involving a metadata update in OR1 During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. So how do snapshots work when we already have the data present on Amazon S3?



























Let's personalize your content