

What you need to know about product management for AI
O'Reilly on Data
MARCH 31, 2020
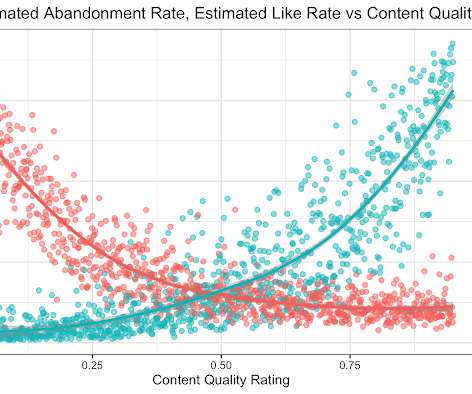
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. Machine learning adds uncertainty. Underneath this uncertainty lies further uncertainty in the development process itself.
















Let's personalize your content