
Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
AWS Big Data
MARCH 4, 2024
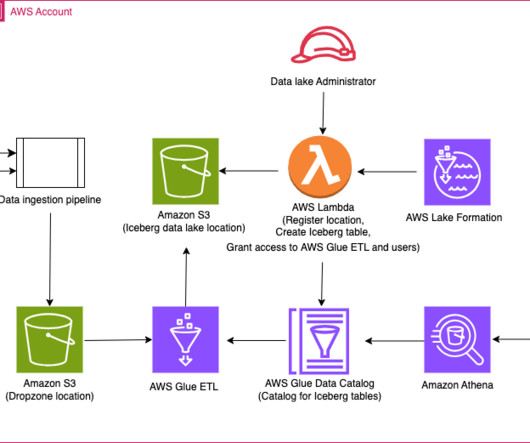
Apache Iceberg manages these schema changes in a backward-compatible way through its innovative metadata table evolution architecture. With Lake Formation, you can manage fine-grained access control for your data lake data on Amazon S3 and its metadata in the Data Catalog. Iceberg maintains the table state in metadata files.



















Let's personalize your content