
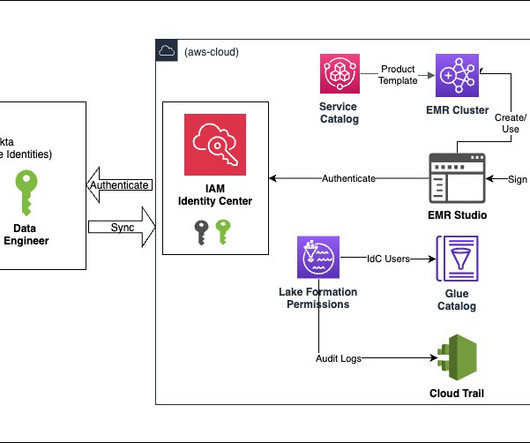
Use your corporate identities for analytics with Amazon EMR and AWS IAM Identity Center
AWS Big Data
APRIL 26, 2024
Set up EMR Studio In this step, we demonstrate the actions needed from the data lake administrator to set up EMR Studio enabled for trusted identity propagation and with IAM Identity Center integration. Lake Formation will automatically specify the correct IAM Identity Center instance. Select Named Data Catalog resources.


















Let's personalize your content