

Use Apache Iceberg in your data lake with Amazon S3, AWS Glue, and Snowflake
AWS Big Data
APRIL 3, 2024
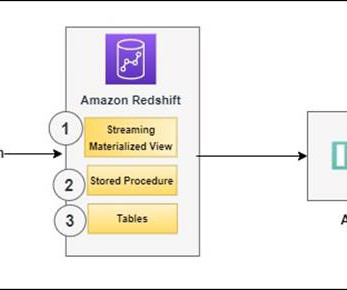
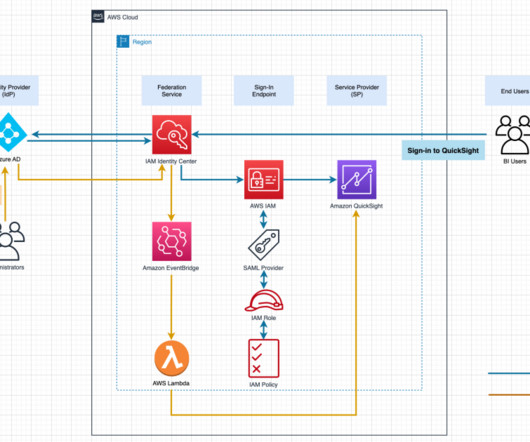
Iceberg tables maintain metadata to abstract large collections of files, providing data management features including time travel, rollback, data compaction, and full schema evolution, reducing management overhead. You can use this same integration to take advantage of the data sharing and collaboration capabilities in Snowflake.





















Let's personalize your content