

Transforming Big Data into Actionable Intelligence
Sisense
MARCH 14, 2021
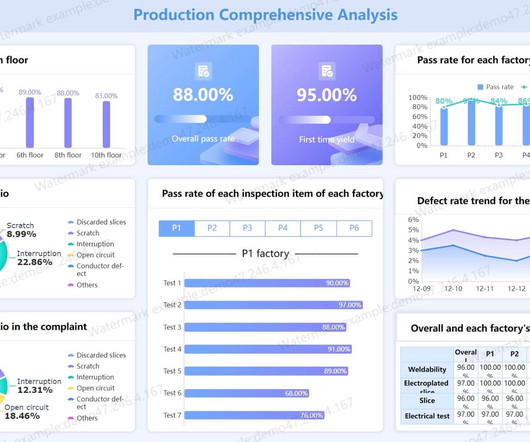
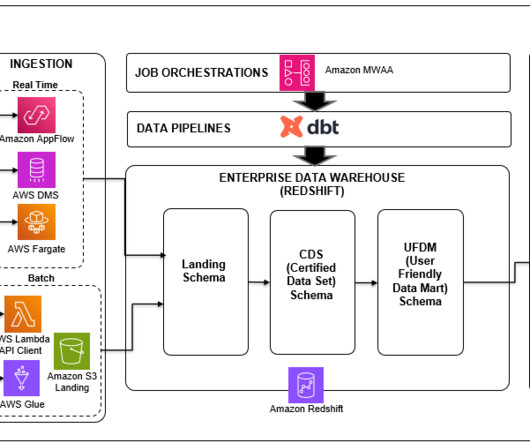
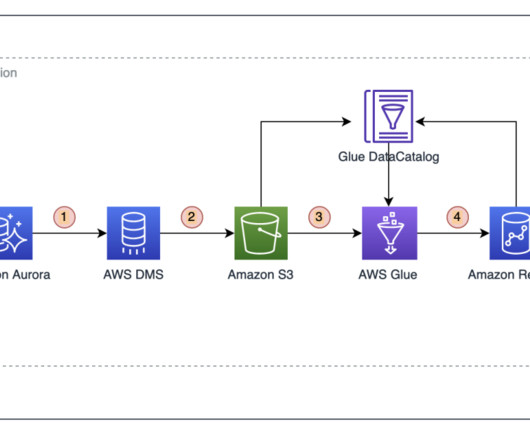
Attempting to learn more about the role of big data (here taken to datasets of high volume, velocity, and variety) within business intelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. Big data challenges and solutions.















Let's personalize your content