7 Steps to Mastering Data Cleaning with Python and Pandas
KDnuggets
MAY 23, 2024
Want to learn data cleaning with pandas? This tutorial will teach you everything you need to know.

 data-cleaning-with-pandas
data-cleaning-with-pandas 
KDnuggets
MAY 23, 2024
Want to learn data cleaning with pandas? This tutorial will teach you everything you need to know.

KDnuggets
SEPTEMBER 5, 2023
This step-by-step tutorial is for beginners to guide them through the process of data cleaning and preprocessing using the powerful Pandas library.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Analytics Vidhya
DECEMBER 21, 2023
Introduction The Pandas Library is a powerful tool in the data analysis ecosystem; it provides a wide range of functions that transform raw data into insightful revelations. Its robust functionality […] The post Unveiling 3 Powerful Techniques with Merge Pandas appeared first on Analytics Vidhya.
O'Reilly on Data
OCTOBER 10, 2023
Second Try: Python and Data in Spreadsheets My next experiment was with a short Python program that used the Pandas library to analyze survey data stored in an Excel spreadsheet. Ethan and Lilach Mollick’s paper Assigning AI: Seven Approaches for Students with Prompts explores seven ways to use AI in teaching. Unfortunately).

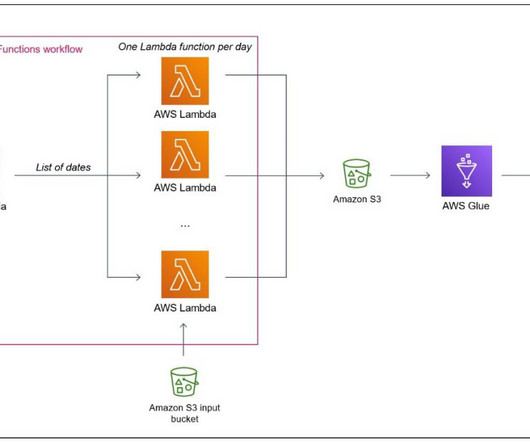
AWS Big Data
APRIL 22, 2024
Dynamic DAGs helps you to create, schedule, and run tasks within a DAG based on data and configurations that may change over time. By harnessing the power of YAML files and the DAG Factory library, we unleash a versatile approach to building and managing DAGs, empowering you to create robust, scalable, and maintainable data pipelines.

AWS Big Data
JUNE 5, 2023
AWS SDK for pandas is a popular Python library among data scientists, data engineers, and developers. It simplifies interaction between AWS data and analytics services and pandas DataFrames. In the previous post , we discussed how you can use AWS SDK for pandas to scale your workloads on AWS Glue for Ray.
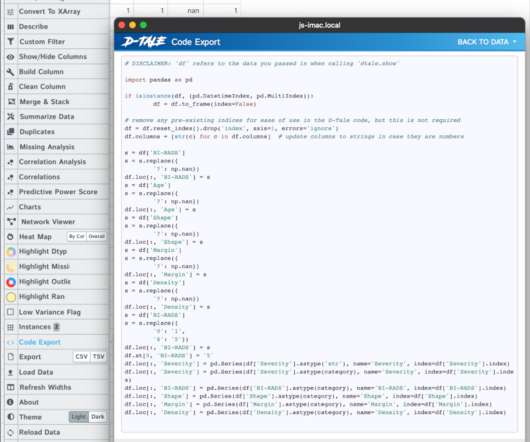
Domino Data Lab
AUGUST 12, 2021
We all have heard how data is the new oil. For data, this refinement includes doing some cleaning and manipulations that provide a better understanding of the information that we are dealing with. The purpose of Data Exploration. Data exploration is a very important step before jumping onto the machine learning wagon.

Expert insights. Personalized for you.




































Let's personalize your content