
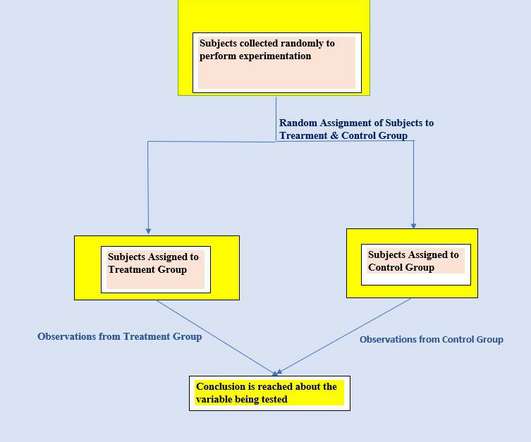
Methods of Study Design – Experiments
Data Science 101
JANUARY 15, 2020
Bias ( syatematic unfairness in data collection ) can be a potential problem in experiments and we need to take it into account while designing experiments. Some pitfalls of this type of experimentation include: Suppose an experiment is performed to observe the relationship between the snack habit of a person while watching TV.













Let's personalize your content