

Salesforce debuts Zero Copy Partner Network to ease data integration
CIO Business Intelligence
APRIL 25, 2024
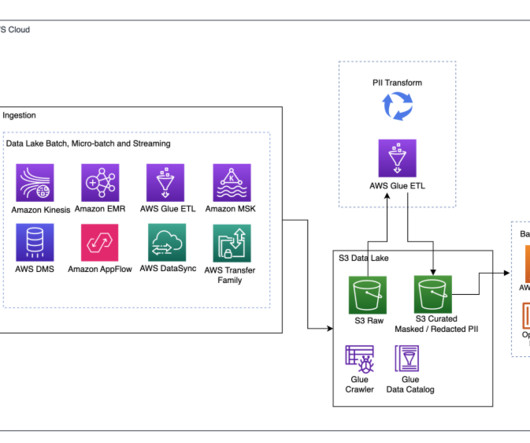
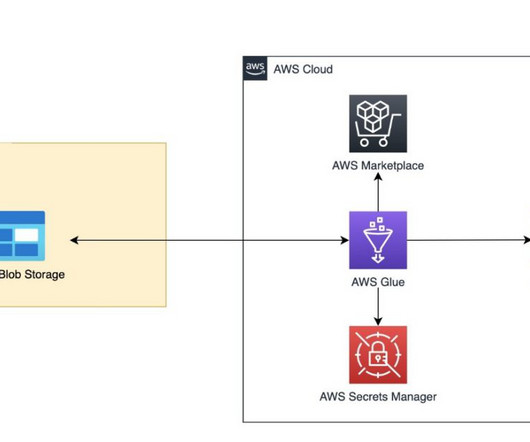
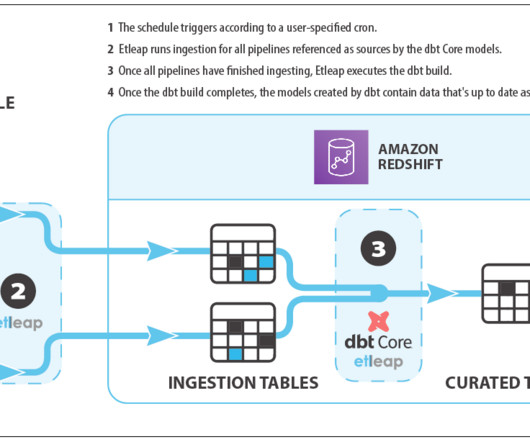
For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external data lake are marked as delayed. Sharing Customer 360 insights back without data replication. Currently, Data Cloud leverages live SQL queries to access data from external data platforms via zero copy.



















Let's personalize your content