

Deploy and Optimize Your Snowflake Environment Faster With Accelerators
CDW Research Hub
JULY 18, 2022
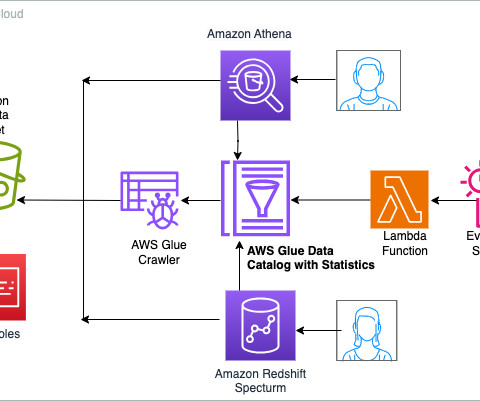
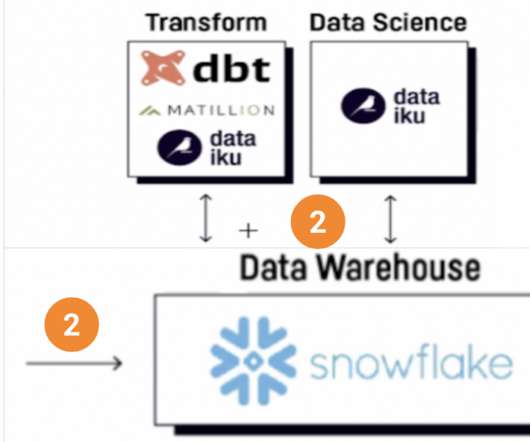
While many organizations understand the business need for a data and analytics cloud platform , few can quickly modernize their legacy data warehouse due to a lack of skills, resources, and data literacy. One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform.
















































Let's personalize your content