

Design a data mesh pattern for Amazon EMR-based data lakes using AWS Lake Formation with Hive metastore federation
AWS Big Data
JUNE 10, 2024
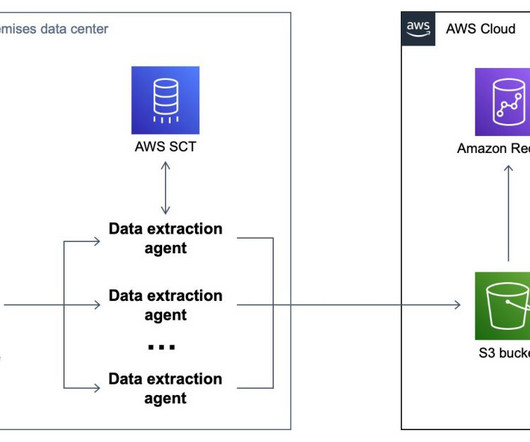
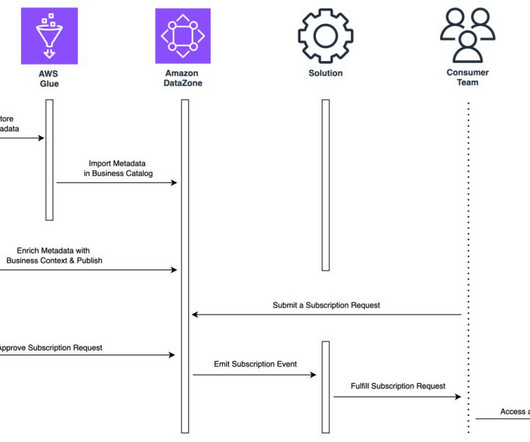
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account.













Let's personalize your content