
Accelerate your data warehouse migration to Amazon Redshift – Part 7
AWS Big Data
OCTOBER 17, 2023
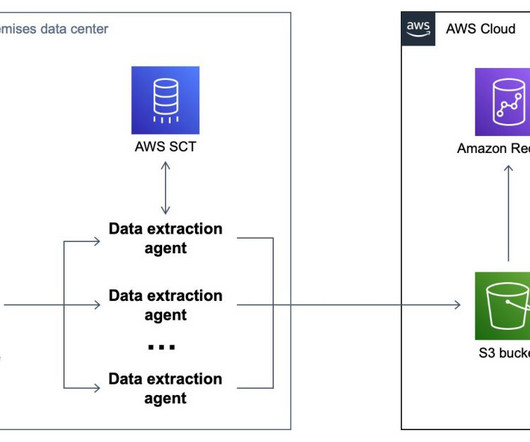
With Amazon Redshift, you can use standard SQL to query data across your data warehouse, operational data stores, and data lake. Migrating a data warehouse can be complex. You have to migrate terabytes or petabytes of data from your legacy system while not disrupting your production workload.





















Let's personalize your content