
Governing data in relational databases using Amazon DataZone
AWS Big Data
MAY 7, 2024
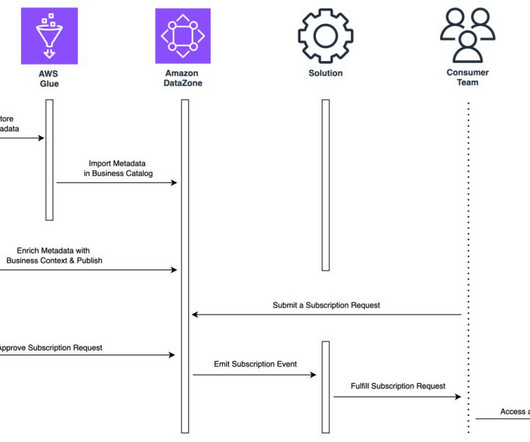
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
























Let's personalize your content