

Enforce fine-grained access control on Open Table Formats via Amazon EMR integrated with AWS Lake Formation
AWS Big Data
JANUARY 17, 2024
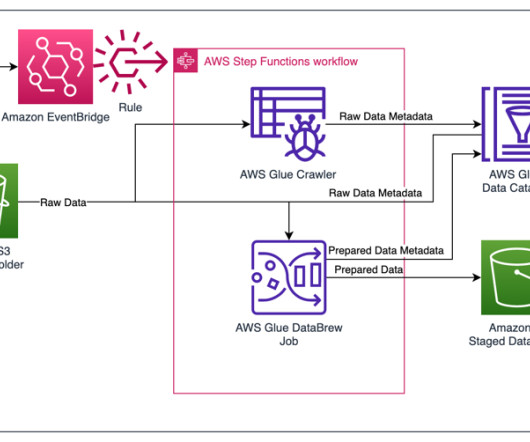
With Amazon EMR 6.15, we launched AWS Lake Formation based fine-grained access controls (FGAC) on Open Table Formats (OTFs), including Apache Hudi, Apache Iceberg, and Delta lake. Many large enterprise companies seek to use their transactional data lake to gain insights and improve decision-making.
















Let's personalize your content