
Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
AWS Big Data
AUGUST 1, 2023
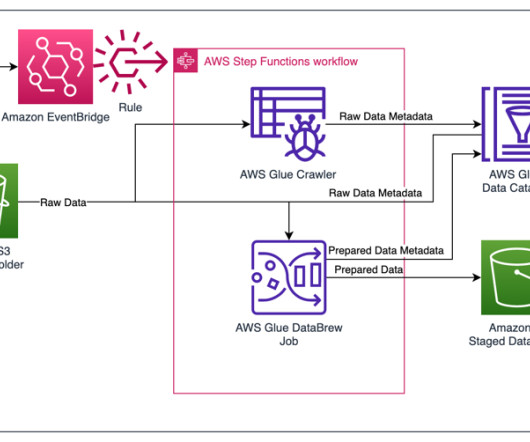
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. For InitialRunFlag , choose Setup.























Let's personalize your content