

How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
AWS Big Data
JUNE 10, 2024
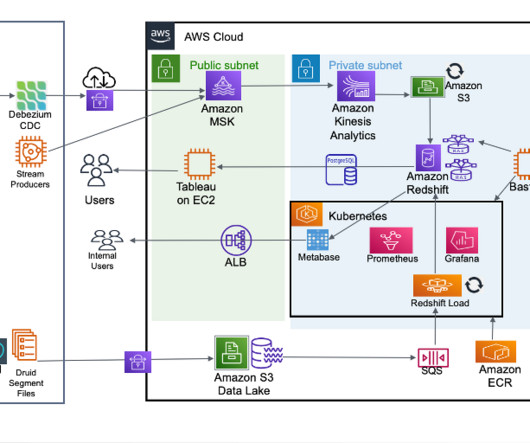
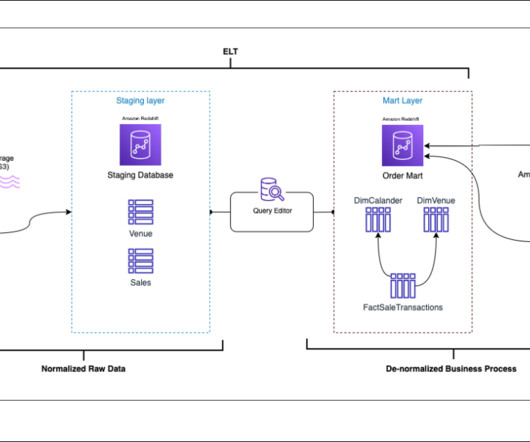
Cloudinary struggled to use this data for additional teams who had more online, real time, lower-granularity, dynamic usage requirements. Making petabytes of data accessible for ad-hoc reports became a challenge as query time increased and costs skyrocketed along with growing compute resource requirements. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()





















Let's personalize your content