
Business Strategies for Deploying Disruptive Tech: Generative AI and ChatGPT
Rocket-Powered Data Science
FEBRUARY 15, 2023
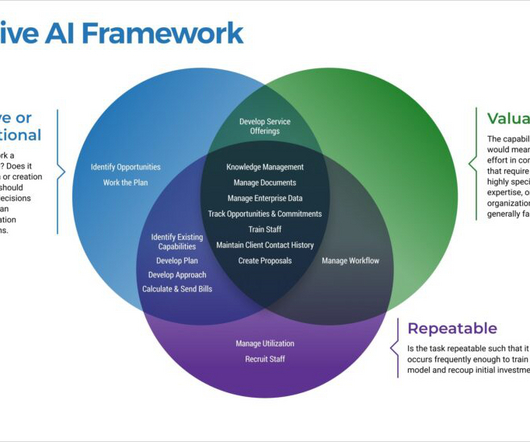
Those F’s are: Fragility, Friction, and FUD (Fear, Uncertainty, Doubt). These changes may include requirements drift, data drift, model drift, or concept drift. encouraging and rewarding) a culture of experimentation across the organization. Test early and often. Test and refine the chatbot. Launch the chatbot.


















Let's personalize your content