
How HR&A uses Amazon Redshift spatial analytics on Amazon Redshift Serverless to measure digital equity in states across the US
AWS Big Data
DECEMBER 5, 2023
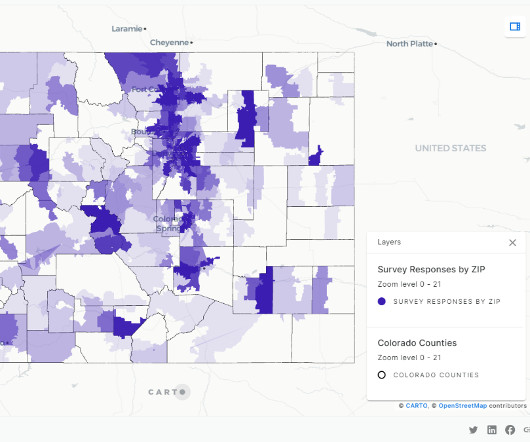
A combination of Amazon Redshift Spectrum and COPY commands are used to ingest the survey data stored as CSV files. For the files with unknown structures, AWS Glue crawlers are used to extract metadata and create table definitions in the Data Catalog. The first image shows the dashboard without any active filters.























Let's personalize your content