

Enhance your security posture by storing Amazon Redshift admin credentials without human intervention using AWS Secrets Manager integration
AWS Big Data
OCTOBER 18, 2023
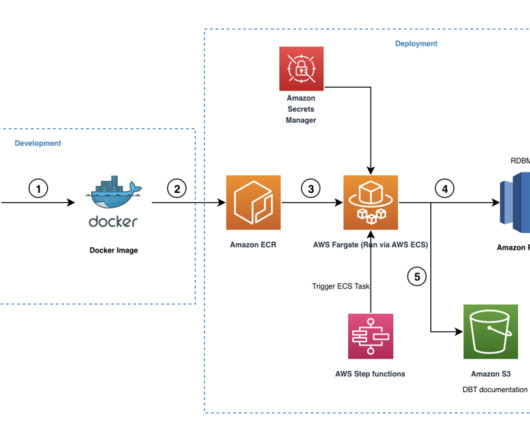
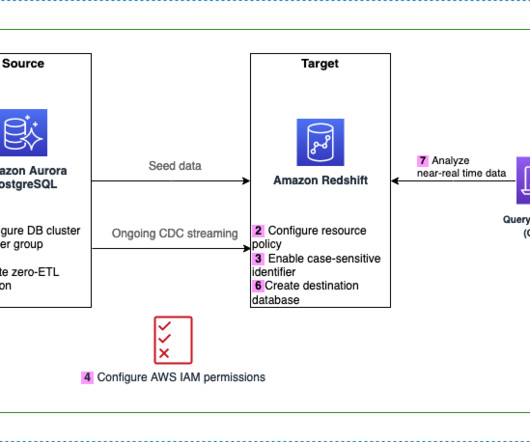
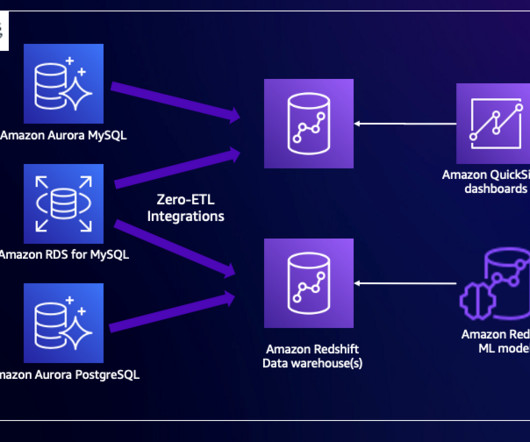
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Provide the information in Cluster permissions and Additional configurations as appropriate and choose Create cluster. Choose Save changes.














































Let's personalize your content