

Enable Multi-AZ deployments for your Amazon Redshift data warehouse
AWS Big Data
NOVEMBER 1, 2023
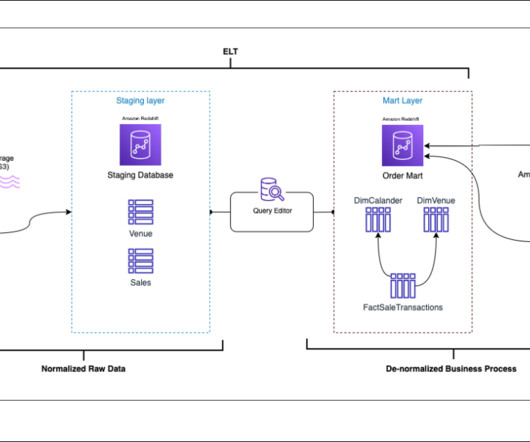
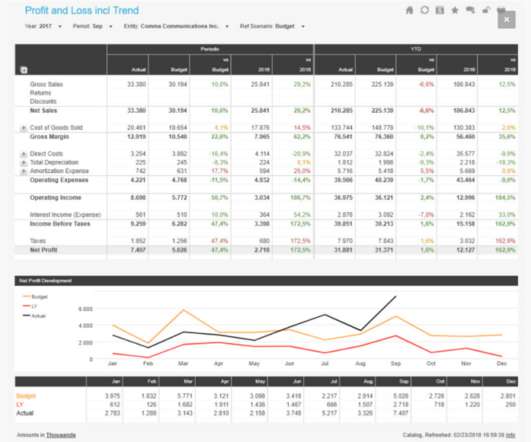
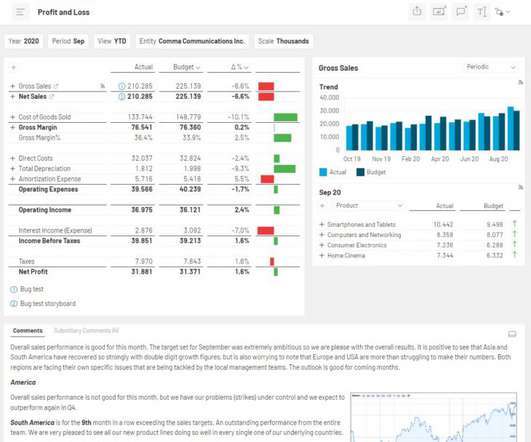
Amazon Redshift is a fully managed, petabyte scale cloud data warehouse that enables you to analyze large datasets using standard SQL. Data warehouse workloads are increasingly being used with mission-critical analytics applications that require the highest levels of resilience and availability.



































Let's personalize your content