

Towards optimal experimentation in online systems
The Unofficial Google Data Science Blog
APRIL 23, 2024
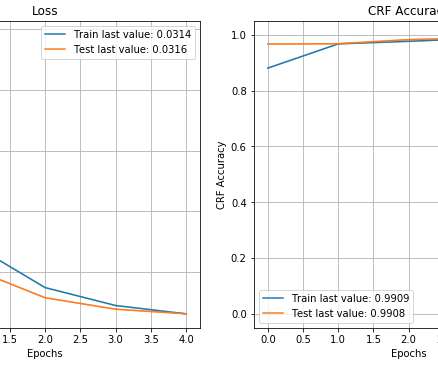
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Figure 2: Spreading measurements out makes estimates of model (slope of line) more accurate. And sometimes even if it is not[1].)














Let's personalize your content