
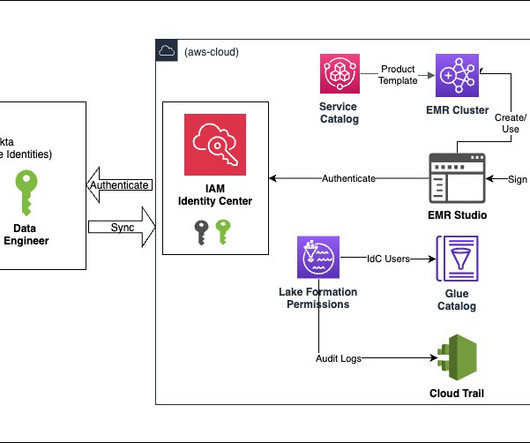
Use your corporate identities for analytics with Amazon EMR and AWS IAM Identity Center
AWS Big Data
APRIL 26, 2024
Use Lake Formation to grant permissions to users to access data. Test the solution by accessing data with a corporate identity. Audit user data access. On the Lake Formation console, choose Data lake permissions under Permissions in the navigation pane. Select Named Data Catalog resources.





















Let's personalize your content