
Measuring Validity and Reliability of Human Ratings
The Unofficial Google Data Science Blog
JULY 18, 2023
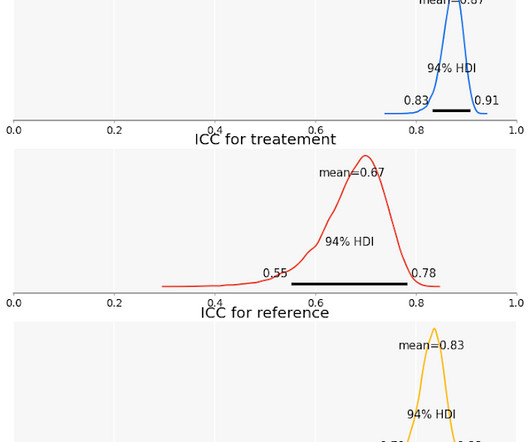
E ven after we account for disagreement, human ratings may not measure exactly what we want to measure. Researchers and practitioners have been using human-labeled data for many years, trying to understand all sorts of abstract concepts that we could not measure otherwise. That’s the focus of this blog post.













Let's personalize your content