

How Aura from Unity revolutionized their big data pipeline with Amazon Redshift Serverless
AWS Big Data
APRIL 4, 2024
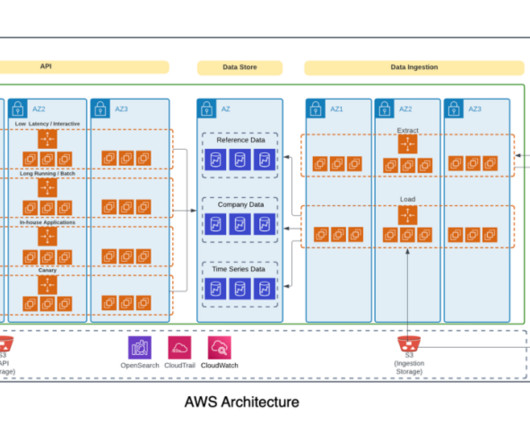
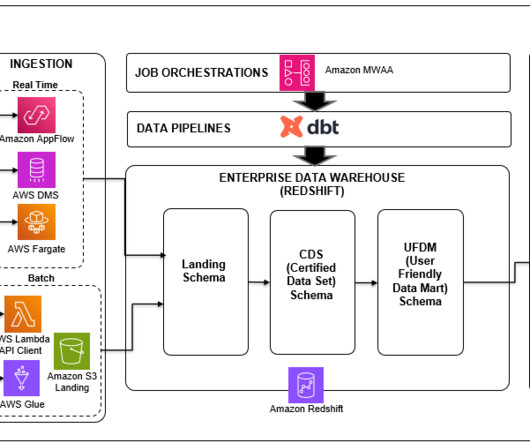
Amazon Redshift is a recommended service for online analytical processing (OLAP) workloads such as cloud data warehouses, data marts, and other analytical data stores. You can use simple SQL to analyze structured and semi-structured data, operational databases, and data lakes to deliver the best price/performance at any scale.


























Let's personalize your content