
Empowering data-driven excellence: How the Bluestone Data Platform embraced data mesh for success
AWS Big Data
FEBRUARY 27, 2024
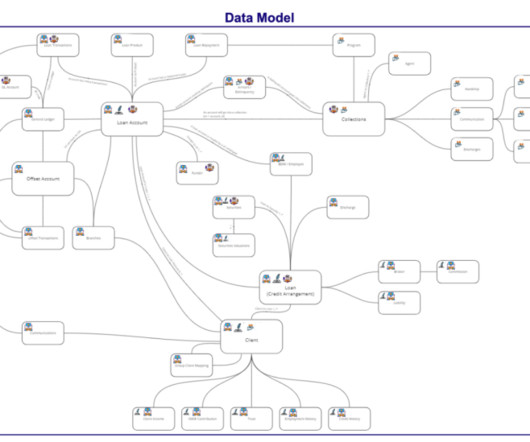
Four-layered data lake and data warehouse architecture – The architecture comprises four layers, including the analytical layer, which houses purpose-built facts and dimension datasets that are hosted in Amazon Redshift. It played a critical role in enforcing data access controls and implementing data policies.

















Let's personalize your content