

How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
AWS Big Data
JUNE 10, 2024
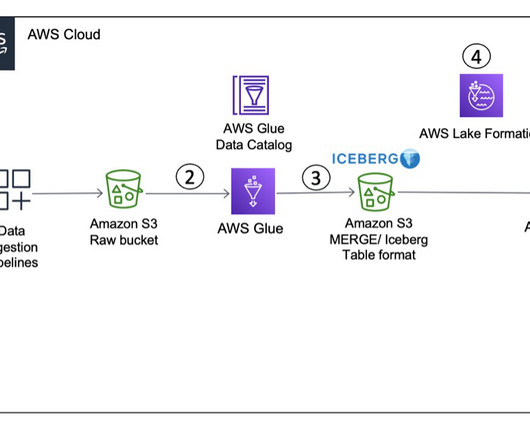
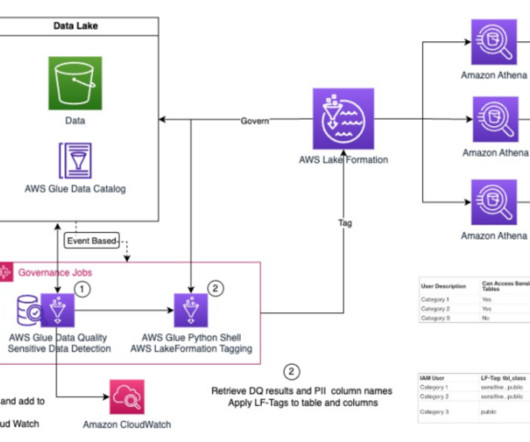
Apache Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for processing engines such as Apache Spark, Trino, Apache Flink, Presto, Apache Hive, and Impala to safely work with the same tables at the same time. The following table shows the cost and time for each query and product.




















Let's personalize your content