
Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
AWS Big Data
APRIL 24, 2023
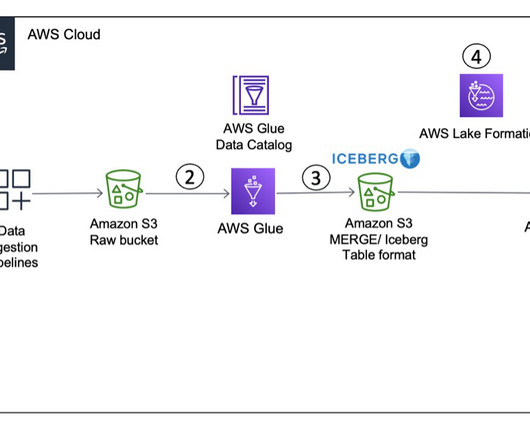
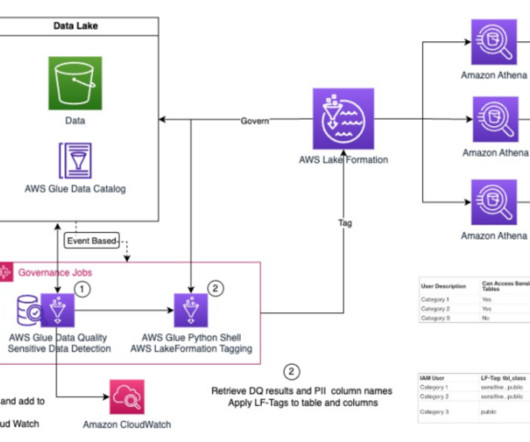
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based data lake, require handling data at a record level.


























Let's personalize your content