
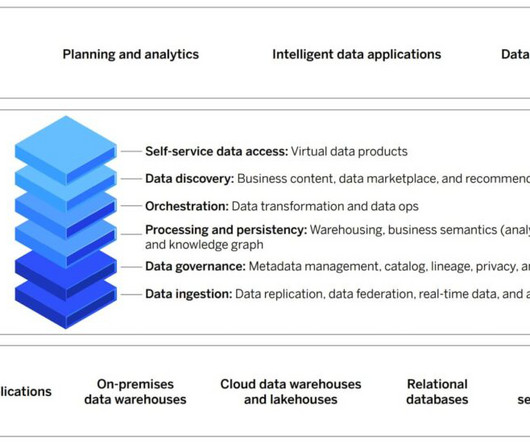
SAP Datasphere Powers Business at the Speed of Data
Rocket-Powered Data Science
MARCH 20, 2023
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. We could further refine our opening statement to say that our business users are too often in a state of being data-rich, but insights-poor, and content-hungry.












































Let's personalize your content