
Monitor data pipelines in a serverless data lake
AWS Big Data
AUGUST 9, 2023
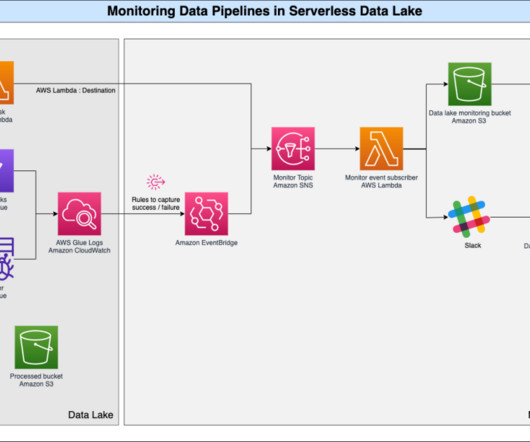
The combination of a data lake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.




























Let's personalize your content