

A Detailed Introduction on Data Lakes and Delta Lakes
Analytics Vidhya
AUGUST 31, 2022
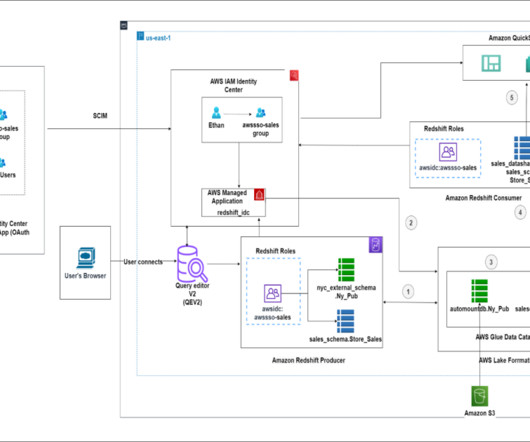
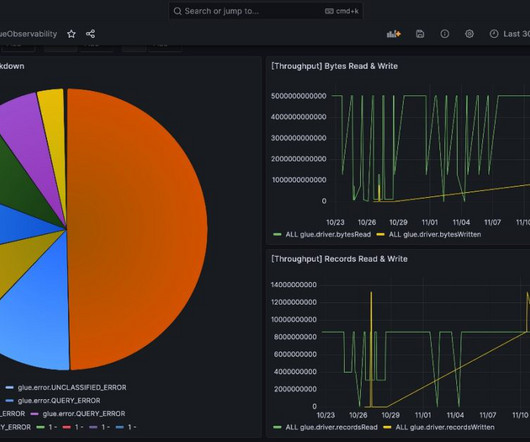
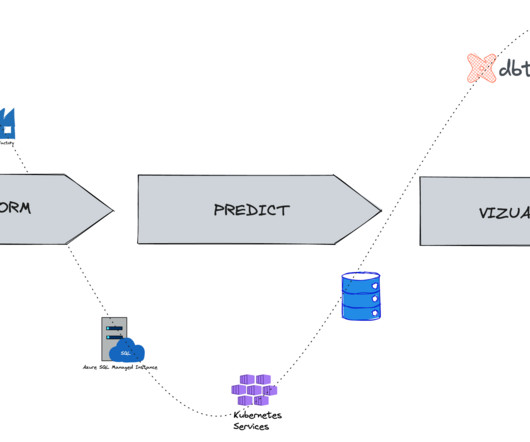
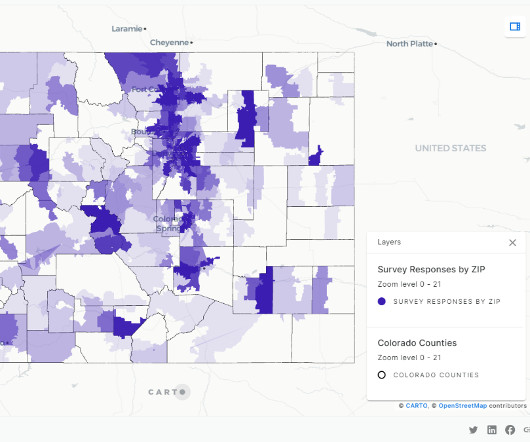
This article was published as a part of the Data Science Blogathon. Introduction A data lake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on Data Lakes and Delta Lakes appeared first on Analytics Vidhya.








































Let's personalize your content