

Amazon DataZone now integrates with AWS Glue Data Quality and external data quality solutions
AWS Big Data
APRIL 3, 2024
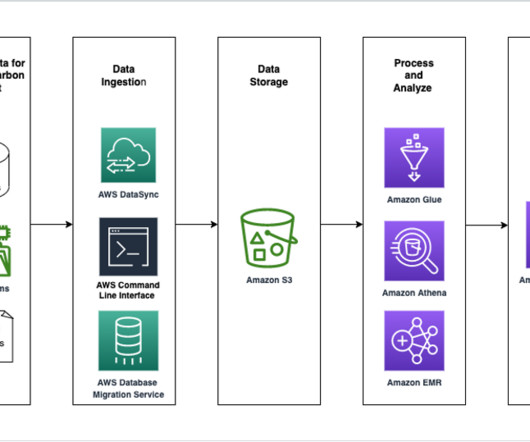
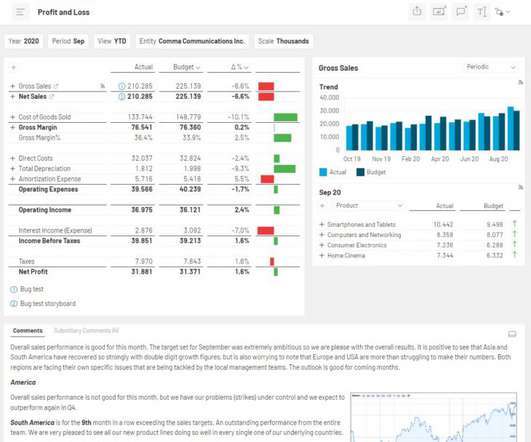
In this example, we use Amazon EMR Serverless in combination with the open source library Pydeequ to act as an external system for data quality. If the asset has AWS Glue Data Quality enabled, you can now quickly visualize the data quality score directly in the catalog search pane.






















Let's personalize your content